Liebe Mathe Experten,
bei der folgenden Aufgabe bin ich am Verzweifeln und hoffe sehr auf eure Hilfe!! Ich habe die Tabelle angehängt:
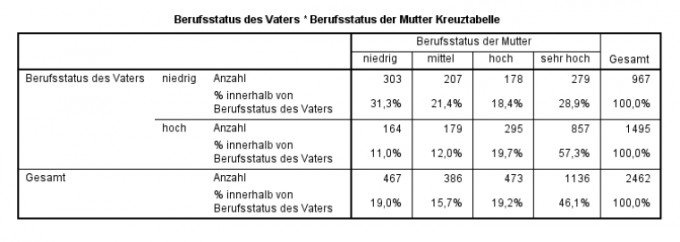
Sie arbeiten als Statistiker für die Partnerbörse „ElitärePartner- Soziale Schließung mit Niveau“ und möchten zwecks einer Algorithmenanpassung anhand der PISA-Studie aus dem Jahre 2012 herausfinden, ob sich auch in diesen Daten bestätigt, dass die Partnerpräferenz bezüglich des Berufsstatus homogen ist.
Sie analysieren den Zusammenhang zwischen dem Berufsstatus der Mutter mit dem Berufsstatus des Vaters. Der Berufsstatus wurde mit Hilfe des ISEI-Index (International Socio-Economic Index of Occupational Status) gemessen.
Sie nehmen an, dass Personen mit einem höheren Status dazu neigen, eine/n statushohe/n Partner/in zu bevorzugen.Bestimmen Sie mit Hilfe eines Chi²-Unabhängigkeitstests, inwiefern Sie in Ihrer Vermutung korrekt liegen und einen statistisch signifikanten Zusammenhang feststellen können. Sie legen das Signifikanzniveau auf 1% fest.
a)Geben Sie die Testgröße an:
Die Testgröße ist der Wert von X² (?) Die angehängte Formel verwende ich für die Berechnung.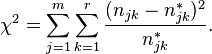
Irgendwie bin ich verwirrt bei dieser Aufgabe und verstehe nicht, was hier n ist? Ist es die Gesamtanzahl in der Tabelle also 2462?
Das Signifikanzniveau liegt bei 1%, also ist α=0.01, damm muss ich die entsprechenden Werte für α (0.01) und m,r einsetzen. Und dann mit χ² 1−α;(m−1)(r−1)2 vergleichen. Stimmt das so?
Ich erinnere mich, dass m und r die Anzahl der Zeilen und Spalten sind, kann das aber nicht genau auf die folgende Aufgabe bzw. Tabelle anwenden?
Kann mir jemand helfen und den Rechenweg erklären?
b)Berechnen Sie die Freiheitsgrade (Angabe ohne Dezimalstellen):
Die Zahl der Freiheitsgerade bestimmt sich doch n−1. Stimmt das?
c)Bestimmen Sie den Ablehnbereich:
Die Frage ist hier also nach dem Ablehnungsbereich K⋅. Ich habe folgende Formel ausgewählt:
K⋅={t;|t|≥ t(n-1;1-(Alpha/2))}. Alpha ist mit 0.01 angegeben ist.
Da ich nicht verstehe, was n in der Aufgabe entspricht, konnte ich leider nicht weiterrechnen. Zum weiteren Vorgehen: Wenn ich das Ergebnis mit der Formel ausgerechnet habe, kann ich einer „t-distrubution Tabelle“ den entsprechenden Wert ablesen, ab dem die Nullhypothese verworfen werden muss (Ablehnbereich)
Könnte mir jemand sagen, ob meine Herangehensweise richtig ist und mir den richtigen Rechenweg darstellen?
d)Hier muss ich anhand der Ergebnisse der Aufgaben zuvor, folgenden Aussagen zustimmten oder ablehnen. Ich hoffe jemand kann mir helfen, was richtig und was falsch ist:
-Der Heiratsmarkt ist von Statushomogenität gekennzeichnet, ich muss die Nullhypothese annehmen.
-Auf dem 1% Signifikanzniveau liegt ein Zusammenhang zwischen den Variablen vor.
-Stimmt es, dass auf einem 5% Signifikanzniveau eine Abhängigkeit wahrscheinlicher
Wäre als auf dem 1% Niveau?