Hallo, ich habe eine evtl nicht ganz so Mathe-Spezifische Frage, aber vielleicht kann mir ja trotzdem jemand dabei helfen.
Ich soll die durchschnittlichen Kosteneinsparungen pro Fall berechnen, die entstehen, wenn man ein Machine-Learning Modell anwendet oder eben nicht.
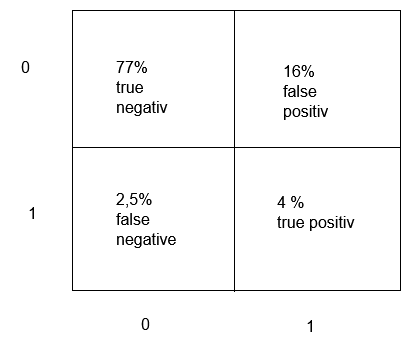
Dafür habe ich hier eine Konfusionsmatrix des Modells und einmal eine Kosten-Tabelle.
Konfusionsmatrix:
Accuracy = 0,82
Recall = 0,62
F1-Score = 0,31
AUC = 0,72
Text erkannt:
\begin{tabular}{|l|l|}
\hline 0 & \\
\hline \( 77 \% \) & \( 16 \% \) \\
true \\
negativ & false \\
positiv \\
\hline 1 & \\
\hline \( 2,5 \% \) false negative & \( 4 \% \) true positiv \\
\hline
\end{tabular}
0
1
Kostentabelle (Kosten pro Fall):

Meine Idee wäre nun einfach die beiden Matrizen übereinanderzulegen. Also:
Wenn das ML-Modell zu 4% Den Kostenfall richtig entdeckt, dann sinken die Kosten in diesem Fall um (25*0.04) = 1.
Wenn das ML-Modell zu 16% den Kostenfall falsch entdeckt, also unnötig, dann entstehen Kosten von (0.16 * 5) = 0,8.
Wenn das ML-Modell zu 77% den Kostenfall richtiger weise nicht entdeckt, entstehen keine kosten.
Wenn das ML-Modell zu 2,5% den Kostenfall fälschlicherweise nicht entdeckt, entstehen kosten von (0,026 * 145) = 3,77
Ist das so falsch gedacht? Und was haben die ML-Modell Kennzahlen wie Accuracy und Recall damit zutun?
Text erkannt:
\begin{tabular}{l|lc}
0 & 0 & 5 \\
1 & 145 & 25 \\
\hline & 0 & 1
\end{tabular}
Text erkannt:
0